Since initial impression-airing, I have been devoting some thought to practical implementation issues, and came up with a preliminary list of questions that I felt would need to be addressed “pre-start-up:” (that is, of course, aside from the obvious need for significant interface infrastructure enhancements to be designed, programmed, and tested)
-
Since this system seems to operate much like a simple sorting algorithm, how will new entries be inserted into the sort once it is already in progress (at the bottom?, top? center of existing?)
-
How will late entries be handled in order to receive a fair exposure? (Those in the last 3 days, 2 days, 1 day; last 3 hours, 2 hours, 1 hour)?
-
In short, the above two issues, illustrate that conducting Elo Pair Review during the design creation cycle would re-produce the same issues that the current system already suffers from.
So, in reference to the above concerns, it strikes me that the preliminary implementation of the “alternating” lab system, as previously proposed here:
http://getsatisfaction.com/eternagame…
…in advance of implementing Elo, could significantly ease the transition to the Elo System.
…however, this “alternating week” system could also be adapted to significantly facilitate the new Elo Pair Review System as well, BUT this would mean the addtion of a third Lab Cycle, “Lab C,” thereby lengthening the cycle by a week.
This scheme would address the above concerns, albeit at the cost of drawing out the cycle to a third week, however, once you take a look at the benefits, perhaps this will not seem too steep a price.
Number 1 above would cease to be an issue, since all entries would be received During Week One before synthesis cut off, meaning that the Elo algorithm would at least be working on a full, complete, stable data-set. During the first week of design, there would be NO Elo Pair Comparisons done; the week would be devoted totally to design creation and submission.
Then at the beginning of Week 2, after design submission cut-off for “Lab A”, the Elo Pair Comparision Process would begin for “Lab A”, and proceed for that whole week, while “Lab B” would simultaneously begin ITS design phase. During this second week of “Lab A’s” Elo Pair Review of designs, there would be NO more design submissions for “Lab A”; the week would be devoted totally to Elo Pair Review. This would give the Elo Pair Review Process more than adequate time for the best designs to “bubble” up to the top, thereby allaying any possible concerns of inadequate pair review affecting results. Also, since all designs would have been submitted prior to cut-off the previous week, there would be no concern about the last and latest entries not receiving a fair shake in the review process. Concurrent with the Elo Pair review for “Lab A,” now remember, the design phase for “Lab B” would be beginning and going into full swing.
At the End of Week 2, the Results of the Elo Pair Review for “Lab A” would be completed and would be published and the top 8 designs sent to the Lab for Synthesis. 'Lab B" would be winding up ITS design phase and getting ready to go to ITS Elo Pair Review Week.
Finally in Week 3, with the “Lab A” Elo Pair Review now completed and the Winners sent off to be synthesized, “Lab A” would close for the week during the synthesis.
Simultaneoulsy, “Lab B” would be completing ITS Elo Pair Review, and would in turn, be preparing to send ITS Top 8 Results to Synthesis.
Meanwhile, “Lab C” would then open for ITS design submission phase, and the whole process would begin again for all 3 Labs.
Here is a quick diagram of the Elo Pair-Review-Enhanced Lab Flow Proposal:
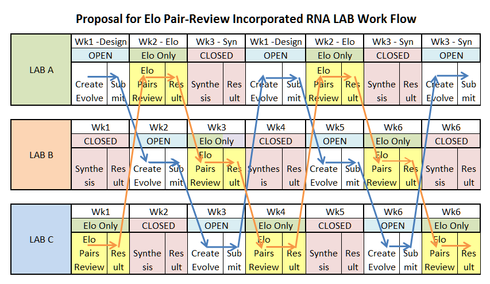
(please click on graphic for larger, clearer view)
I think the added organization, and separation of effort achieved in creating these clear-cut phases may be more than worth the cost of lengthening the cycle to a third week to accommodate the Elo Pair Review Process.
Thanks & Best Regards,
-d9
