Hi everyone,
We are excited to announce an update to our scoring system for switch lab puzzles. I would first like to thank our data analysis expert Hanjoo Kim for his time and effort improving our scoring system - he has put in a huge amount of work and it really shows! I would also like to thank Brourd for giving us reminders and ideas to help us improve the scoring method. Thanks all around!
Without further ado, here is a link to an image archive of our new scores:
https://www.dropbox.com/sh/qdumrhmn5l…
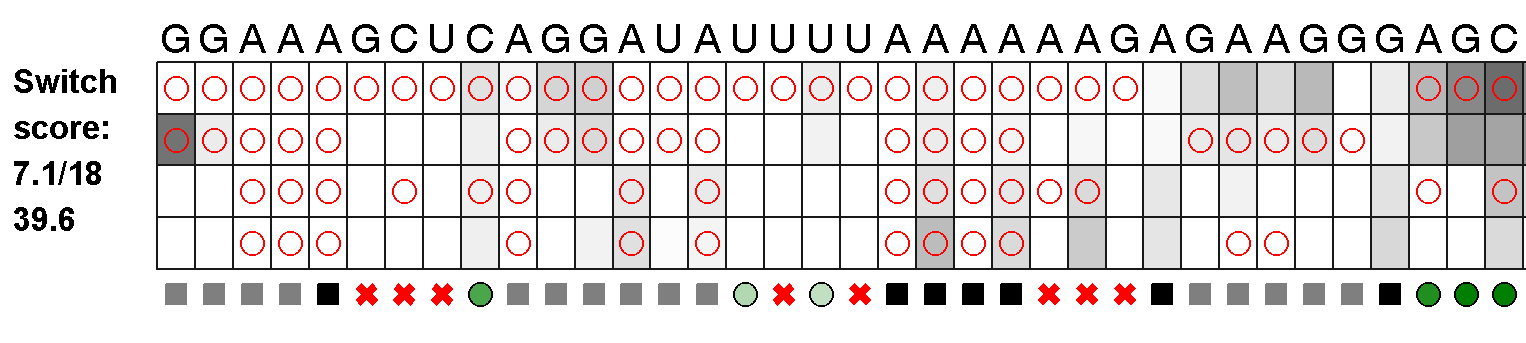
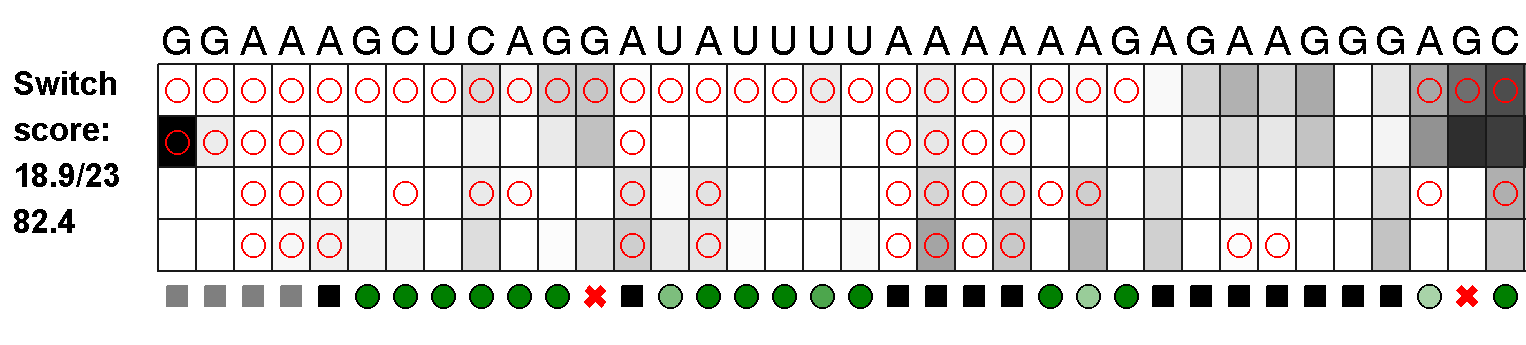
This link should contain two folders, each full of .png image files corresponding to every switch round, going back to the Simple RNA Switch. (In lab, we refer to the round by their number in the history of EteRNA, so that explains why the earliest one is Round 51). One folder contains images for all of the scores you have seen before, by our old metrics; another folder contains the same data, analyzed and scored by several new procedures! We consider the new scoring scheme to be an improvement over the old one - many of the scores have improved, but a handful have dropped as well. We think the new one is more fair and more accurate.
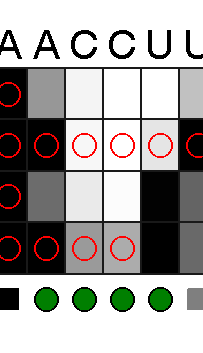
A note on how to read the image files - you will notice 4 rows of data for each RNA. The top row is SHAPE data (as a reminder, SHAPE can react with just about any unpaired nucleotide) without FMN, the second row has SHAPE data with FMN, the third row has DMS data (DMS reacts with any unpaired A or C) without FMN, and the fourth row has DMS data with FMN.
There are a few important differences to the scoring scheme. Perhaps the most obvious one is that we are now including the aptamer nucleotides in the switch score - in previous we had omitted them. As I said, this has boosted the scores for many people and occasionally reduced scores. The other major difference is that Hanjoo has reworked the data analysis protocol. Before we show all the data to the players, the data must be normalized - essentially, we have to compute how light and dark the bands should be for each experimental run. Hanjoo has kindly improved the normalization strategy and we think this will yield more accurate final results that better reflect the experimental results.
A few reminders and explanations of how we score the data:
With the switch labs, we care about whether or not the RNA appears to switch when we add FMN. While we only show the target structure and the most stable structure in the game, RNA actually frequently exists as a mixture of related shapes when it is in solution. I gave a brief explanation of this in the following link:
https://getsatisfaction.com/eternagam…
So, because there may be many different RNA shapes in solution at any time, all of them can contribute to our data! Mostly, we care if your RNA responds to FMN - if there is a change in the pattern of dark bands, it means that your RNA is binding FMN at least a little. However, the FMN binding shape may not make up 100% of the RNA molecules in the test tube, so sometimes it doesn’t look like the RNA has fully switched. In cases where the dark bands move in the correct direction (light to dark or dark to light), but don’t go all black or all white, we give partial credit. Rhiju covered this in a post, with the link below:
https://getsatisfaction.com/eternagam…
In the image files, you will see green circles of various darkness - the more green, the more credit. A light green circle may only get 0.2 or so of a point.
As I mentioned above, we are now scoring the aptamer nucleotides. While they are unpaired, not all of them are expect to receive full protection from FMN. A perfect FMN binder would have reactivities in the presence of FMN as follows:
AGGAUAU AGAAGG
0001000 000000 [SHAPE]
0001010 001100 [DMS]
1 means dark, a reaction, normally associated with unpaired. 0 means white, no reaction, the nucleotide is protected from the chemical probe by FMN (or typically because it is in a base pair). Without FMN around, these nucleotides will behave as normal paired (white bands) or unpaired (dark bands) nucleotides.
Now, the most important part. Please give us feedback! The player community has proven to be very observant, and we hope you can help us find improvements, errors, or anything that isn’t clear about the new scoring system and results. If you find results that still seem to be scored inaccurately (or mysteriously), please post in this thread about them. We will look forward to any feedback you can give us!
As a final note, you’ll see that the few most recent rounds are missing from the new scoring system data files. The last few rounds have had an assortment of errors due to several recent issues in lab - we have retaken all the lower quality data and are getting around to reanalyzing it with the new scoring system. Those image files will hopefully be available soon.
We are excited to get any feedback on the new scoring system!
Best,
Tom