I have been running a few tests by making puzzles, to see a bit more about how the bots react to designs with short stacks. As to further test my hypothesis, that short-stems in lab are hard to get to bind. It is as I mentioned above:
Rna strands are hold together by hydrogen bonds. And what I observed was that the shorter the strings got, the harder it was to keep them in place and get them bind up with each other. So short contact surface = bad contact.
Thanks to Rhiju for the idea that I could ”test this hypothesis further by creating short-stem challenges in silico for bots in the ‘player puzzles’…”
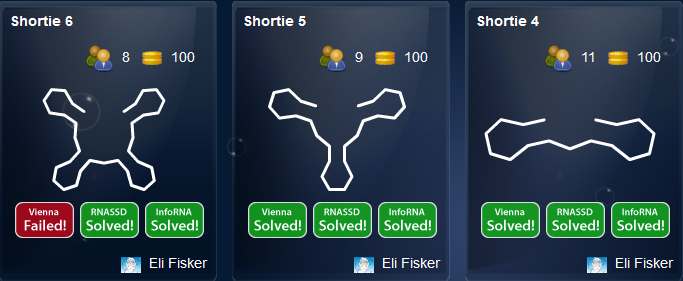
Here is Brourd’s uncomplicated series. As numbers of stems grows, more bots gets in trouble.

Vienna first gets in trouble in the ones with most legs in my shortie series. But tetraloops are much easier to stabilize than triloops. So these puzzles are not as pressured as Brourd’s, though the stacks are shorter.

I have some examples on that putting in more legs of this type, will get the bots in trouble. Check my turtle puzzles for more examples. The more legs, the more bot trouble, mainly to Vienna and SSD.
The bots don’t like too many repeats of similar shapes. A quite sure way to gets the bots in trouble, is to cram more short strings in to one leg and tripple it. So more short stacks pr. leg, more bot trouble.



Starryjess campfire is made of many short strings. Here the lack of symmetry and repetition, does not help the robots, propably as the numbers of short strings is high.

But equal length strings generally seem to worsen the problem for the puzzlesolving algorithms, as they open up much more options for repetitive sequence with leaves the puzzle prone to mispairing.
Symmetry, especially if on more than one axis enhances the problem with equal length strings. Also as general rule, the bigger puzzle, the harder to solve for the bots. It only takes one spot the bots can’t solve, to make them fail. I have tried run InfoRNA in big puzzles to see how it would do. To my surprice it only got stopped at a few spots, but else were able to solved a big puzzle.

Freywa found with his Kyurem puzzles an almost certain method to making the bots go nuts.

- they have short stacks (most of the length of 4 nt and shorter)
- the stacks are of relatively equal length
- bulges placed at sharp angles in relation to each other.
ROBOTS IN LAB COMPARED WITH PUZZLESOLVING ROBOTS
I decided also to take a look at the labs in general, as some of them originated from player puzzles. So the bots have solve some of them in both lab and as puzzles.
LABS WITH SIMILAR LENGTH OF STRINGS (many strings with same length)
The general picture is that bots scored in the 80’ties or worse in designs with similar length of strings if they were fairly short (4 nt and down). Chalk outline, Making it up as we go and FMN binding Branches. The picture was the same in the Branches lab, where more than half the strings of equal length and 4 nt’s long. But here the multiloops size might play in as well.


The bots had no big problem with solving the puzzle. Neither had players.
Nupack did fair in The star lab, here the strings are of equal length which opens up to mispairing. But as I think, equal length strengs when longer, are less prone to mispairing.
LABS WITH SHORT STRINGS (energeticly pressured)
Here the bots overall did bad. Like in really bad. Kudzu were similar hard on the puzzlesolving bots and lab designing bots. Except our own  Nupack scored 84% as highest. And human players had a hard time making winning designs too. Hinting that shortstring designs are really hard to get to stick together. Which might not be surprising when we are up against getting very short strings forming hydrogen bonds with each other. And those strings have to be mainly the strong GC-pair. Forcing us in direction Christmas tree. The two high scoring designs in Kudzu (95%) and Water strider (92%) have a high GC-pair ratio on 76% and 79%.
Nupack scored 84% as highest. And human players had a hard time making winning designs too. Hinting that shortstring designs are really hard to get to stick together. Which might not be surprising when we are up against getting very short strings forming hydrogen bonds with each other. And those strings have to be mainly the strong GC-pair. Forcing us in direction Christmas tree. The two high scoring designs in Kudzu (95%) and Water strider (92%) have a high GC-pair ratio on 76% and 79%.


The Water strider lab actually never got a winner in lab. Vienna and Nupack as puzzle solving algorithms failed solving the puzzle. But the puzzles do not pose problems for players to solve as puzzles.
The water strider has opposed to Kudzu, more similar length strings, which opens up to mispairs. It also have more multiloops and there are more sharp angles between strings more strings. All of this putting more energetic pressure on the puzzle.
LABS WITH LONG STRINGS
Nupack did great in The cross lab and One bulged cross, where the strings were very long. Same in the finger lab. The finger lab had no multiloop, which might lessen the pressure. And though it it have very equal length strings, they are not short. Long string designs seem to have a greater tolerance to pattern that will elsewhere not be tolerated. I think it is because it helps break repetition and thus prevents misparing better. See my post Rule sensitivity according to length of string.
Nupack however did worse in the similar shaped Bulged star with 1-1 loops in the arms. 1-1 loops can have a stabilizing effect on a lab design, as the G-G mismatch actually can pair up in the loop. But here the design gets full of small 3 nt long strings. The design have 9 small 3 nt’s length string and one with the length of 4 nt’s. GC-pairs at ends of each string is the strongest solution, but leaves the string both GC-heavy and with a very repetitive pattern. If all of 9 small ones gets solved with GC-pairs at the end of the strings, it opens up to a huge amount of mispairing opportunities.
LABS WITH WARIED LENGTH OF STRINGS
Nupack did great in the asymmetry lab, where string lengths were varied and okay in Bends and ends sampler lab. Nupack did better in shape test lab, that had more varied length of the strings. (92%) All the bots ”in silico” had no trouble at all. So designs with varied leght of strings is the easiest for the lab bots and the puzzle solving bots.


Conclusion
A majority of the designs that puzzle solving bots failed, have short stacks and many equal length stacks. The number of short stacks affect how well the bots do with the puzzles. The more short stacks, the harder time they have solving the puzzles.
Repeats of a structure and symmetry on more than one axis, gives bots a harder time solving the structure. The bigger the puzzle, the worse for the bots.
The designs that posed least problems to both puzzlesolving bots and the lab bots were designs with varied leght of strings in the design. The bots also did best in designs that did not have too many short strings.
The puzzle solving bots did better than the lab bots (Vienna and Nupack) with solving designs with short strings. This suggesting that the energy model of the bots allow for more short strings than nature finds fit. That it is hard to make proper hydrogen bindings between short stretches of string.
Eg. the puzzle solving bots did mostly fine on Chalk outline and Making it up as I go, where the lab bots did bad. Players were not able to solve Making it up as I go. Chalk outline were solved by one player, but the rest of the solutions were below 90%, suggesting it was a hard lab.
These are the tendencies I see this far, based on the data we have.




























{kind=link}
{kind=link}
{kind=link}